What Killed Blackboard
How a six-year cloud migration without deployment automation turned a $3 billion EdTech acquisition into a $1.7 billion bankruptcy — and what the divested business unit that built the pipeline did differently.

In September 2025, Anthology — the company that owned Blackboard, the most recognized name in education technology — filed Chapter 11 bankruptcy with $1.7 billion in debt and annual interest payments consuming 41% of total revenue. Six months later, it emerged as a debt-free shell of its former self, having sold off two of its three business segments for a combined $120 million.
The same month Anthology filed for bankruptcy, a former Blackboard business unit — Transact Campus, divested in 2019 for $720 million — was completing its integration into Roper Technologies following a $1.6 billion acquisition. Same parent company. Same industry. Same compliance requirements. Opposite outcomes.
The difference was not strategy. It was not market timing. It was not product vision. The difference was whether the organization had built the operational infrastructure to deploy software reliably across multiple environments at scale — and what happened when it hadn't.
The Migration That Never Ended
Blackboard announced its move to a fully SaaS model on AWS in 2014. The goal was straightforward: migrate all clients off self-hosted and managed-hosting deployments to a multi-tenant cloud architecture.
Six years later, only about half of clients had migrated to SaaS. The company was running three completely different deployment models simultaneously:
- Self-hosted: Customers running Blackboard on their own data centers
- Managed-hosting: Blackboard operating dedicated instances in its own data centers
- SaaS: Multi-tenant cloud deployment on AWS
Each model required different code paths, different support structures, different security configurations, and different operational procedures. As Phil Hill — the leading EdTech analyst who tracked Blackboard's trajectory for over a decade — documented: the company had "an albatross around their neck with the need to support different code bases and deployment models."
This was not a technology problem. It was a deployment orchestration problem. The company was trying to migrate thousands of institutional clients to the cloud without a system that could manage the migration itself.
Three Deployment Models, Zero Automation

The evidence of operational paralysis accumulated publicly:
Software that hadn't been updated in two years. Blackboard's worst outage in years, in April 2020, was traced to infrastructure that had gone untouched for 24 months. In an industry where competitors were shipping weekly, Blackboard had environments that hadn't seen a deployment in two years — not because nothing had changed, but because deploying was too risky and too manual to attempt without a crisis forcing it.
Forced migration without migration capability. In 2020, Blackboard announced that self-hosted support would end by December 2023 and managed-hosting by December 2022. This created a two-dimensional migration nightmare: institutions had to move hosting models and migrate from Classic to Ultra (the modernized UI) simultaneously. Faculty had to manually recreate course content or use conversion tools that "may require adjustments." Institutions that "just don't have the resources to migrate" were being told to migrate anyway.
Overprovisioning as the default. When COVID-19 drove a 4,800% increase in Blackboard Collaborate usage, the company's response — documented in their own AWS case study — was to overprovision. As AWS noted: "Blackboard erred on the side of overprovisioning; in the long term, however, the company needed a more cost-efficient solution." They eventually implemented autoscaling and Spot Instances, but this was reactive optimization of a single product, not systematic infrastructure-as-code across the entire estate.
Every feature, every security patch, every performance optimization had to be tested and deployed three different ways. The combinatorial explosion of configurations — three hosting models times two UI versions times thousands of institutional customizations — was not a scaling challenge. It was an impossibility without automation.
The $3 Billion Bet That Compounded the Problem

In October 2021, Anthology — a company formed by Veritas Capital through a roll-up of Campus Management, Campus Labs, and iModules — acquired Blackboard for approximately $3 billion. The acquisition was funded almost entirely by debt.
What Anthology inherited:
- An incomplete SaaS migration six years in
- Three deployment models requiring parallel operational support
- A declining market share against Canvas (cloud-native from day one) and D2L Brightspace (which had forced a complete SaaS migration)
- 30+ products with overlapping codebases across the combined entity
- $1.7 billion in debt requiring $185 million in annual interest payments
The financial trajectory was swift and brutal:
- Revenue: $530M (FY2023) → $450M (FY2025) — down 15%
- EBITDA: $33M → $4M — down 88% in two years
- Annual interest payments: $185M — 41% of total revenue
By December 2024, Anthology skipped its interest payments. By September 2025, it filed Chapter 11. The court filings tell the story in numbers: $1.7 billion in funded debt, $185 million in annual interest payments, and EBITDA of $4 million — meaning the company's operating profit couldn't cover a single week of debt service.
The company attempted a $90 million cost-saving plan and a $250 million refinancing in 2024, but the structural economics were irrecoverable.
Why Competitors Survived

The competitive landscape makes the operational failure visible:
Canvas (Instructure) was built cloud-native from its founding. No migration problem. No legacy deployment models. One codebase, one deployment pipeline, simultaneous feature delivery to all customers. Instructure's trailing twelve-month revenue reached $634 million — surpassing Anthology's total by 41%.
D2L Brightspace made the painful decision to force all clients off self-hosting and managed-hosting to pure AWS-based SaaS over 3-4 years. They lost some clients during the transition, but emerged as a "true cloud-based LMS company" with $215 million in revenue and $11.6 million in total debt. Not $11.6 billion. $11.6 million.
Blackboard tried to avoid the hard decision — maintaining legacy deployment models to retain customers while simultaneously migrating to the cloud. Without deployment automation to manage this complexity, they ended up with the worst of both worlds: the operational costs of three deployment models and the competitive disadvantage of slow feature delivery.
The pattern is clear in the numbers: D2L, which forced the migration, has negligible debt and iterates rapidly. Blackboard, which delayed the migration, accumulated $1.7 billion in debt and couldn't iterate at all.
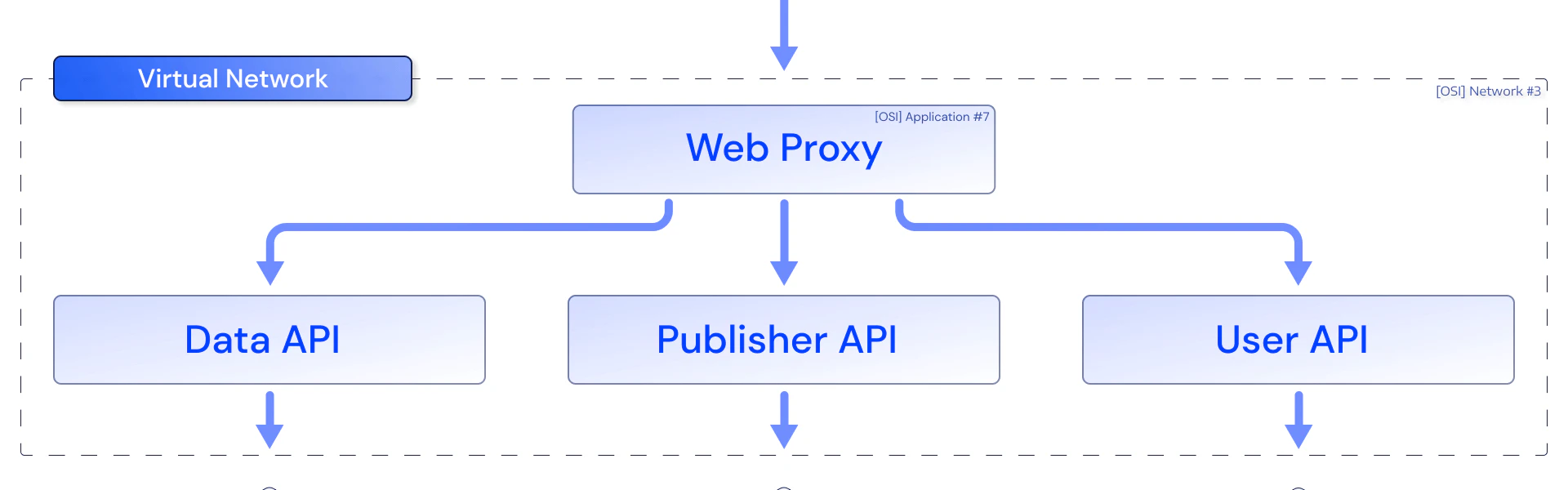
The Divested Business That Built the Pipeline
In April 2019, Blackboard divested its Transact business unit — the payments and campus commerce division — to Reverence Capital Partners for approximately $720 million.
Blackboard Transact — approximately one-third of Blackboard — was a good representation of the parent company's operational maturity. The division handled students' financial information, banking data, and controlled the physical access systems that lock and unlock doors across campus. This was the closest thing to critical infrastructure outside the DOD — not a consumer app where a breach means you apologize and offer credit monitoring.
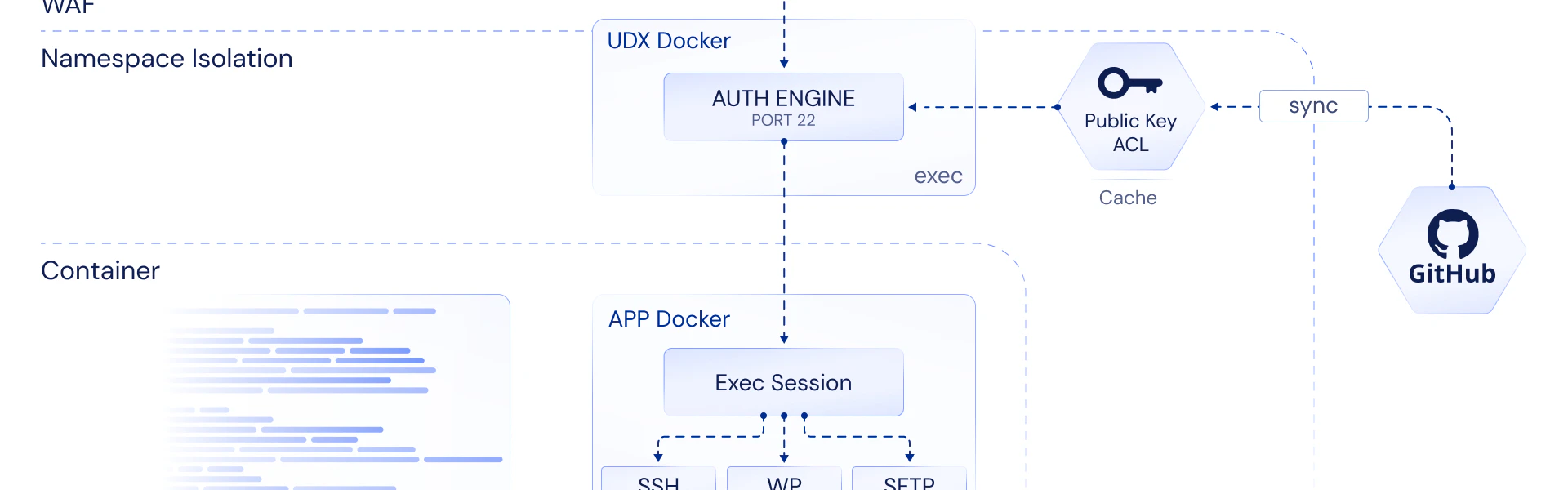
In 2018, the greenfield project — Mobile Credential, the mobile credentialing platform that would eventually reach 80%+ market share — had no deployment automation. Products across three verticals were either not releasing automatically or doing ArgoCD-style GitOps that only reconciled within Kubernetes. There were no solutions to spin up or manage resources outside of Kubernetes. The organization had already purchased Octopus Deploy but hadn't set it up. The VP of Engineering bought it because he wanted variable scoping — managing configuration variables with different values across environments. He never mentioned the concept of a release pipeline, which is what the organization actually needed.
The platform wasn't even running on Kubernetes. It was running on Azure Service Fabric — Microsoft's pre-Kubernetes container orchestrator, now deprecated with a migration deadline of March 2027. The deployment tooling needed to handle Service Fabric, not just Kubernetes manifests.
What got built was a release orchestration pipeline aligned with how the organization actually worked:
- Developers handed off feature builds to the QA team
- QA signed off on the story and release, then handed it to User Acceptance Testing (UAT)
- UAT was managed by a completely different department
- That department ensured the release could reach production
- At each stage, approvals were required before the release could proceed further
Each product ended up with five to seven environments in its pipeline. The pipeline took code developers wrote, packaged it into deployable artifacts, and deployed in sequence — with rules, state awareness, and explicit halt conditions at every phase. It produced all artifacts and evidence any PCI DSS or SOC 2 auditor would ever ask for. Pipeline phases were aligned with organizational departments and procedures: it was clear when work was handed off and who was responsible for approval.
The compliance drivers were real. PCI DSS Requirement 6.4 mandates separate development and test environments, testing of security impact, and separation of duties. SOC 2 CC8.1 requires formal authorization of production changes. The institutional client base demanded this — universities handling financial aid, meal plans, and physical access control need to prove that different versions of code are tested in different environments before reaching production.
The results were measurable:
- Time from developer finishing work to customer delivery: one year → under a week (sometimes a day)
- Tracked deployments: single digits → 30,000+ per year (DORA classifies elite at 1,460/year — this was 20x elite)
- Developer experience: settings were easy to find, easy to iterate on, and integrated into whatever interface developers already used
- Every deployment was tracked, versioned, and deployable into other environments — environments that represented lifecycle stages with organizational controls
The business trajectory:
- April 2019: Divested for ~$720M (Reverence Capital, with $300M+ in equity)
- 2019-2024: Operational transformation adopted across all three verticals
- June 2023: 1 million mobile credentials provisioned, 80%+ market share, $230M+ processed through mobile credentials
- 2024: 1,800+ institutions, $49B+ in annual payments processed, 250M+ contactless transactions
- August 2024: Acquired by Roper Technologies for $1.6 billion (projected $325M revenue, $105M EBITDA)
Roper already owned CBORD — Transact's biggest competitor, acquired in 2008 for $367 million. CBORD served 750 colleges and 1,700 healthcare licensees. The combined entity now has dominant market position in a campus card systems market valued at $1.65 billion globally in 2024 and projected to reach $3.72 billion by 2033.
While Anthology's Blackboard was losing $80 million in revenue and watching EBITDA collapse by 88%, the former Blackboard division that built the deployment pipeline more than doubled its valuation.
Technical Debt Becomes Financial Debt

Blackboard's bankruptcy is typically discussed as a private equity story — leveraged buyout, excessive debt, declining market. That framing is accurate but incomplete. The debt was serviceable if the business could grow or even maintain revenue. It became fatal because the business couldn't execute.
And it couldn't execute because it lacked the operational infrastructure to do so.
Without deployment automation, cloud costs become unmanageable. People who worked at Blackboard during this period describe an organization that essentially bankrupted itself with cloud costs. There may not be a single document that proves this definitively, but the structural argument is compelling: if Blackboard's operational maturity was anything like what existed in the Transact division in 2018, they would have had no idea what anything would cost in the cloud — and even if they had known, they would have had no mechanism to change it. Every environment is manually configured. Overprovisioning becomes the default because the cost of an outage — manual investigation, manual rollback, manual redeployment — vastly exceeds the cost of spare capacity. And this is before getting into high availability and scaling with demand.
Without infrastructure-as-code, every environment is a snowflake. A security patch that works in the SaaS environment breaks the managed-hosting environment because someone made a manual change six months ago that was never documented. The patch for managed-hosting breaks a self-hosted client because their Java version is two years behind. Each fix creates a new configuration branch. The configuration space grows faster than the team can map it.
Without deployment visibility, you can't trace what changed. When Blackboard's worst outage hit in April 2020 — traced to software unchanged for two years — the diagnosis itself was the tell. In a system with deployment records, the answer to "what changed?" is immediate. In a system without them, the answer is "we're not sure, but we think nothing changed, and that's actually the problem."
The iteration speed problem compounds everything. Without deployment automation, the feedback loop between identifying a problem and validating a fix stretches from hours to weeks. Developers stop experimenting. Product teams stop requesting features. The organization enters a defensive posture where the primary goal is avoiding breakage, not delivering value. Revenue declines follow.
The Sequencing Error
Blackboard made a critical sequencing error that is common in enterprise cloud migrations:
They announced the destination before building the road.
The SaaS migration was announced in 2014. The deadline for self-hosted support was set for 2023. The Ultra UI migration was launched in parallel. But the deployment automation — the system that would make all of these transitions manageable, traceable, and fast — was never built.
The result was predictable: forced migrations without the operational capability to support them. Institutions were told to migrate, but the migration process itself was manual, fragile, and under-resourced. The support burden of running three deployment models consumed the engineering capacity that should have been building the pipeline to eliminate them.
Compare this to the approach that worked at Transact: build the pipeline first, then use it to accelerate everything else. The pipeline made deployments easy, traceable, and fast. Developers adopted it because it solved their immediate bottleneck. Product teams used it because it turned "deploy to five environments" from a project into a button press. The pipeline was the prerequisite for everything that followed.
This is not specific to education technology. It is the fundamental lesson of every failed enterprise cloud migration: the migration tool is not the cloud provider. It is the deployment pipeline.
What GitOps Couldn't Do
The GitOps model — put desired state in Git, let a controller reconcile the cluster — appears to solve the deployment problem. It is elegant for a single Kubernetes cluster with a stable configuration.
But Blackboard's challenge was never a single Kubernetes cluster with a stable configuration. It was:
- Three fundamentally different deployment models requiring different operational procedures
- Hundreds of institutional clients with different configurations, compliance requirements, and migration timelines
- Infrastructure spanning Kubernetes, bare metal, managed hosting, and client-operated data centers
- A UI migration happening simultaneously with a hosting migration
- Compliance and data residency requirements that varied by institution and jurisdiction
GitOps addresses one dimension of this problem — the Kubernetes dimension — and treats the rest as someone else's problem. The reconciliation loop answers "does the cluster match Git?" It does not answer "has this institution been migrated safely?" or "does this configuration work in all three deployment models?" or "can we roll back this institution without affecting the 200 institutions sharing the same SaaS tenant?"
What Blackboard needed was not a reconciliation controller. It was an orchestration pipeline — one that could manage deployments as ordered, stateful operations across heterogeneous infrastructure, with explicit halt conditions, promotion gates, and audit evidence generation. The kind of pipeline where environments are runtime parameters, not Git paths — where adding a new institutional environment means adding a YAML file, not spinning up new infrastructure, new credentials, and new operational procedures.
The core issue is deeper than tooling. Organizations don't need deployment automation for CI/CD. They need it to prove they have a sound process. Every change must be traceable. Every change must be tested exhaustively before deployment. Changes must be manifested and declared as artifacts with sequential versioning. A proper pipeline has sequential phases aligned with organizational structure — and Git alone isn't sufficient, because what gets done in Git isn't all that's needed for a release to be deployed into production.
GitOps reconciliation tools solve the wrong problem for regulated environments. They answer "does the cluster match the repo?" They don't answer "has this change been approved by QA, tested by UAT, and authorized for production by the release management team?" In an environment governed by PCI DSS and SOC 2, the second question is the one the auditor asks.
GitOps is deceptively simple. It solves the demo perfectly. But at enterprise scale — with multiple deployment models, compliance boundaries, cross-platform workloads, and hundreds of tenant configurations — the simplicity becomes the constraint. The things it doesn't handle are the things that determine whether a cloud migration succeeds or fails.
The Bankruptcy Arithmetic
Here is the arithmetic that killed Blackboard:
Revenue: $450 million and declining 8% annually Interest payments: $185 million (41% of revenue) EBITDA: $4 million (before interest) Gap: -$181 million per year
No amount of cost cutting closes a $181 million annual gap on a $450 million revenue base. The company would have needed to grow revenue by 40% while simultaneously eliminating nearly all operational overhead. That was structurally impossible for an organization that couldn't deploy a software update without manual intervention across three different infrastructure models.
The private equity structure made the math fatal, but the operational immaturity made the math inevitable. A company that could deploy rapidly, iterate on features, onboard clients quickly, and optimize cloud costs could have grown into its debt. Blackboard couldn't do any of those things.
The emergence from bankruptcy tells the story: Blackboard sold its SIS and ERP business to Ellucian for $70 million and its CRM and student success business to Encoura for $50 million. The combined sale price for two of three business segments was $120 million — 4% of the $3 billion acquisition price four years earlier.
Same Industry, Opposite Outcomes
Blackboard (Anthology) - Acquired for ~$3B (2021) - No deployment automation at scale - 6+ years of incomplete cloud migration - EBITDA: $33M → $4M (-88%) - Three simultaneous deployment models - Annual release cadence - Outcome: Chapter 11 bankruptcy
Transact Campus - Divested for ~$720M (2019) - Full deployment orchestration pipeline - Operational transformation in 2 years - Growing valuation to $1.6B exit - Unified pipeline across multiple targets - Weekly release cadence - Outcome: Acquired by Roper for $1.6B, combined with CBORD to dominate the market
Same parent company. Same EdTech industry. Same higher-education compliance requirements. Same institutional customers.
One built the deployment pipeline. One didn't.
The Lesson
Blackboard's bankruptcy is usually framed as a cautionary tale about private equity leverage, or about market disruption by cloud-native competitors, or about the difficulty of acquiring and integrating large software companies.
It is all of those things. But underneath all of them is a simpler truth: Blackboard could not deploy software reliably across its own infrastructure. Everything else — the stalled migration, the overprovisioned cloud resources, the slow feature delivery, the customer attrition, the revenue decline that made the debt unserviceable — was a consequence of that single operational failure.
The deployment pipeline is not a DevOps nice-to-have. It is not a line item that can be deferred while the organization focuses on "strategic priorities." It is the mechanism through which strategic priorities become reality. Without it, strategy is aspiration. With it, strategy is execution.
Transact built the pipeline and turned $720 million into $1.6 billion. Blackboard didn't build the pipeline and turned $3 billion into bankruptcy.
The infrastructure you build to deploy your software is, ultimately, the infrastructure that determines whether your software — and your company — survives.